續上一篇機器學習 挑戰 - Day 4,
我們今天繼續詳細研究一下如何套用 tensorflow.keras.sequential 來預測BTC的價格。
首先,我們先導入數據,然後我們把closing price數據分成4個列表:Closing price of date-3days, date-2days, date-1day & date
基本上,是要用三天前的closing price去推測將來的closing price。
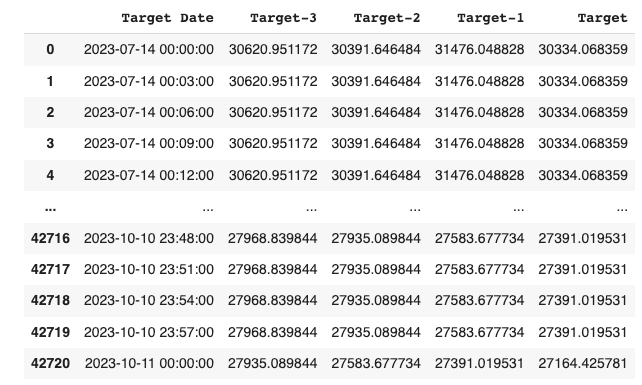
再來,把日期,[Target-3, Target-2, Target-1]列為 X,而Target則列為 Y。
def windowed_df_to_date_X_y(windowed_dataframe):
df_as_np = windowed_dataframe.to_numpy()
dates = df_as_np[:, 0] #all the rows, first col
middle_matrix = df_as_np[:, 1:-1] #all the rows, 2nd, 3rd and 4th col
#len(dates) = no. of observations, columns being observed, varibles we are observing (just 1: Closing price)
X = middle_matrix.reshape((len(dates), middle_matrix.shape[1], 1))
Y = df_as_np[:, -1] # all the rows, last COL
return dates, X.astype(np.float32), Y.astype(np.float32)
最後把數據分成3組:dates_train(8成的數據用來訓練),dates_val (10成的數據用來確認),dates_test(10成的數據用來測試)。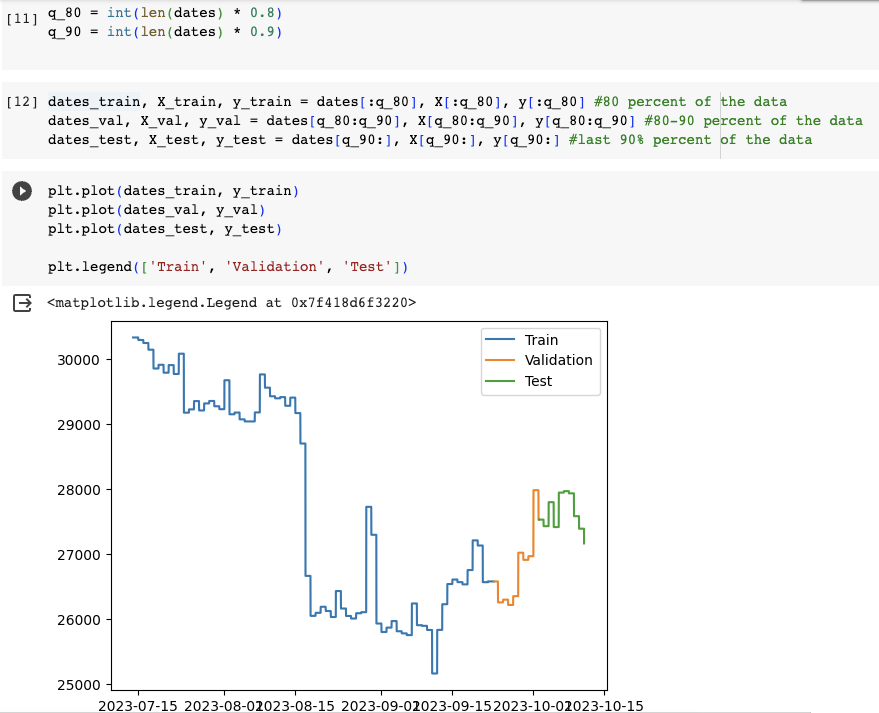
終於可以開始設定machine learning了。

以上看似簡單,但我想要詳細的了解設定了什麼。
Layers
# 1st layer is input layer
layers.Dense(256, input_dim=3, activation="relu", name="input")
第1個數值256代表節點(nodes)的數量。
只有第1層可輸入input_dim參數,其值取決於我們正在處理的數據集的性質。在表格數據集中,input_dim將等於數據集中的列數。可以使用.shape[-1]獲取該數字。在我的情況下,我輸入 "3" 到input_dim中。
最後,激活函數(activation)是將節點的加權輸入從節點轉換為輸出的函數。
Rectified linear activation function or ReLU 是一個分段線性函數,如果輸入為正,則直接輸出輸入,否則輸出為零。由於使用它的模型更容易訓練並且通常達到更好的性能,因此它已成為許多類型的神經網絡的默認激活函數。
ReLU看起來和表現像線性函數,但實際上是一個非線性函數。該函數在無法通過將函數的斜率等於0來找到最準確點的情況下非常有用(使用Stochastic Gradient Descent SGD)。
對於第一個以後的層,無需輸入維度。你要加上第二以及第三層才能織成一個neural net(類神經網路)。每一層的代表節點都會再增加你的training parameter(重複訓練)但很重要的一點是,越多代表節點不表示預測會更準確。
最後一層應該是輸出層,它必須反映我們希望從神經網絡中接收的值數量。例如,我們只想預測未來的單一價格,因此最後一層的單位數必須為1。
最後我們把所有層次都組合在一起,為模型添加一個名稱,並使用.summary()打印我們的架構摘要。摘要會跟我們講在執行訓練時會重複訓練幾次。
最重要的列是"輸出形狀"(output shape),因為它顯示了我們的數據在神經網絡的各個層中如何變化。"參數數量"列指示神經網絡可以調整的參數數量。在數學術語中,這是我們優化問題的維數數。
如果我們有驗證集和測試集,我們可以使用model.evaluate(X_test, y_test)來評估模型。
今天就先講到這,我們下一章繼續看看。
以上方法大部分是參考且引用Been Guan Teo的Medium文章。有興趣大家可以看看。
其他參考資料:
https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
https://towardsdatascience.com/stochastic-gradient-descent-clearly-explained-53d239905d31
https://keras.io/api/layers/recurrent_layers/lstm/
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
對 dbt 或 data 有興趣?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加
Ref:
https://levelup.gitconnected.com/20-pandas-functions-for-80-of-your-data-science-tasks-b610c8bfe63c

